Learn how designing system architecture works in the real world. A practical guide to defining requirements, choosing patterns, and building scalable systems.
Tired of your architecture diagrams becoming ancient relics the moment you draw them? What if you could generate UML diagrams, technical docs, and even get refactoring suggestions automatically, right from your code? That’s what we’re building with DocuWriter.ai—a living architecture that’s always in sync.
Designing a system’s architecture is really about creating the blueprint for success. It’s where you define the core structure, how all the different pieces will talk to each other, and how the whole thing will meet the demands of the business. These aren’t small decisions; they dictate how your system will perform, scale, and evolve for years to come. Think technology stacks, data models, communication patterns—the high-level choices that have massive downstream consequences.

Before you even think about sketching a diagram or writing a single line of code, there’s a critical phase that makes or breaks a project: defining the non-functional requirements (NFRs). These are the “hows” of the system—how it performs, how reliable it is, how secure it needs to be.
I’ve seen too many teams jump past this, and it almost always leads to painful, expensive redesigns down the road. It’s a classic mistake.
The problem is that teams often settle for vague goals like “the system needs to be fast” or “it has to be scalable.” That’s not good enough. To build a solid architecture, you have to translate those fuzzy ideas into hard, measurable metrics that tie directly back to what the business actually needs. This is where the real work begins.
The heart of this early stage is getting in a room with stakeholders and asking the right questions. Your job is to dig deep and turn ambiguous business needs into concrete technical specs. It’s less about what the system does and more about how it behaves under real-world pressure.
Let’s take an e-commerce platform. The business goal might be “we need a great user experience during a flash sale.” A seasoned architect hears that and immediately starts breaking it down into numbers:
This level of precision is absolutely non-negotiable. The financial difference between 99.9% uptime (nearly 9 hours of downtime a year) and 99.999% uptime (just over 5 minutes a year) is massive. To get this right, you first have to internalize some essential system design principles.
To make sure nothing gets missed, I rely on a checklist to guide those stakeholder conversations. It forces everyone to cover all the bases, from performance and security to maintainability. While the full scope of what software architecture is can get pretty deep, nailing the NFRs makes everything that follows so much clearer.
Here are the key areas I always focus on:
By meticulously defining these NFRs upfront, you create a shared, unambiguous understanding of what success looks like. This groundwork ensures the architecture you build is designed to solve the right problems from day one—creating a system that’s not just functional, but genuinely resilient.
Tired of your architecture diagrams falling out of sync with your actual code? Let DocuWriter.ai handle it. It automatically generates UML diagrams, technical docs, and even refactoring suggestions straight from your codebase, so your architecture is always clear and up-to-date.
A truly resilient architecture is never a giant, monolithic block. Think of it more like a well-organized collection of independent, specialized components that work together to get the job done. Breaking down a big system into these smaller pieces is called system decomposition, and frankly, it’s where great design really begins.
The real challenge isn’t just splitting things apart; it’s drawing the right boundaries between the services you create. Get this wrong, and you end up with “chatty” components, tangled dependencies, and what’s often called a distributed monolith. You get all the complexity of microservices with none of the actual benefits.
But when you get it right? Your teams can develop, deploy, and scale their parts of the system independently. This is a game-changer for moving faster and reducing risk.
One of the best strategies I’ve found for identifying these natural boundaries is Domain-Driven Design (DDD). At its core, DDD pushes you to model your software around the business it serves, not just the technical layers. Instead of thinking “database layer” or “UI layer,” you start thinking in terms of business capabilities.
Let’s take a simple e-commerce platform. Using DDD, you’d quickly identify a few core domains:
Each of these is a distinct Bounded Context, to use the official DDD term. It’s basically a conceptual boundary where a specific domain model makes sense and stays consistent. By aligning your service boundaries with these contexts, you end up with services that are highly cohesive—they do one thing, and they do it exceptionally well.
This whole approach ensures your services are separated by business function, not just some arbitrary technical line. The payoff is a system that’s far easier to understand, maintain, and evolve, simply because the software’s structure mirrors the business’s structure.
Once your service boundaries are mapped out, the next move is to define exactly how they’ll talk to each other. This is all about crafting well-defined Application Programming Interfaces (APIs) and data contracts. Think of an API as the formal agreement that spells out how one service can communicate with another.
A clear contract is absolutely vital for maintaining loose coupling. Loose coupling is the principle that a change in one service shouldn’t force a change in another, as long as the contract between them holds up. For instance, the Order Management service doesn’t need to know how the Payments service processes a credit card. It just needs to know it can call the processPayment endpoint with the right data and expect a clear success or failure response.
This fosters incredible team autonomy. The team working on the Payments service can completely gut its internal logic or even swap payment providers. As long as they honor that API contract, the Order Management service is none the wiser. This modularity is a cornerstone of agile, healthy system design. When your teams can work in parallel without tripping over each other, productivity just takes off.
Don’t let your system’s complexity outpace your ability to understand it. Let DocuWriter.ai automatically generate diagrams and technical docs from your codebase, ensuring your architecture is always clear and up-to-date.
Once you’ve broken your system down into logical pieces, you’ve hit a major fork in the road: picking an architectural pattern. This isn’t about jumping on the latest trend—it’s a critical decision that will dictate your system’s performance, complexity, and how much it costs to maintain down the line.
Whether you go with a monolith, microservices, or something event-driven, you’re laying the foundation for how your entire system will run and grow. The right choice comes down to your project’s specific needs, your team’s skillset, and where you see the product going. A pattern that’s perfect for a massive enterprise could easily crush a startup with unnecessary complexity. The goal is to make a smart, informed decision that works for you now and later.
Monolithic architecture gets a bad rap these days, often dismissed as outdated, but that’s way too simplistic. A well-designed monolith is a single, unified system where all the components are built and deployed together. For many projects, especially early on, this is actually the smartest and fastest way to go.
Development is more direct, debugging is simpler, and you only have one thing to deploy. If you’re a small team or the business domain is still taking shape, a monolith gives you the speed you need to get to market quickly without getting tangled up in the complexities of distributed systems. The trick is to keep it modular internally so you don’t end up with a “big ball of mud.”
Microservices, on the other hand, structure an application as a collection of small, independent services. Each service is built around a single business function and can be developed, deployed, and scaled all on its own.
This is a game-changer for complex systems, large dev teams, and situations where you need to scale one part of the app without touching anything else. Think of an e-commerce platform beefing up its product-search service for Black Friday traffic without having to redeploy the user-profile service. When you get to this point, comparing Microservices vs Monolithic Architecture becomes a key architectural decision.
This flowchart gives you a simple way to think about the choice when designing your system.

Ultimately, you have to ask yourself if the freedom to scale and deploy independently is worth the significant operational headache that comes with managing a distributed system.
Event-driven architecture (EDA) is all about systems that produce, detect, and react to events. In this setup, components talk to each other asynchronously through event messages, which creates a highly decoupled system. When a user places an order, for example, an OrderPlaced event gets published. Other services, like Inventory and Shipping, can then listen for that event and react accordingly, without ever needing to know about the ordering service itself.
This pattern is fantastic for building responsive and resilient applications. If the shipping service goes down, the OrderPlaced events can just queue up until it’s back online. No data is lost, and the whole system doesn’t grind to a halt. The global Architecture, Engineering, and Construction (AEC) market, which is expected to hit $16.3 trillion in 2025, leans heavily on these kinds of decoupled designs to manage massive project lifecycles. For instance, Building Information Modeling (BIM) is now used in over 60% of large projects and has been shown to reduce design errors by up to 40%.
To help you weigh the options, here’s a quick comparison of the most common patterns.
Each of these patterns has its strengths and weaknesses. Your job is to analyze the trade-offs in the context of your specific business goals. If you want to go deeper, our guide on common software architecture patterns is a great next step.
Are your architecture diagrams turning into ancient relics the second you finish drawing them? Imagine generating UML diagrams, technical docs, and even getting smart refactoring suggestions automatically, right from your code. That’s what we’re building at DocuWriter.ai—a living architecture that’s always in sync.
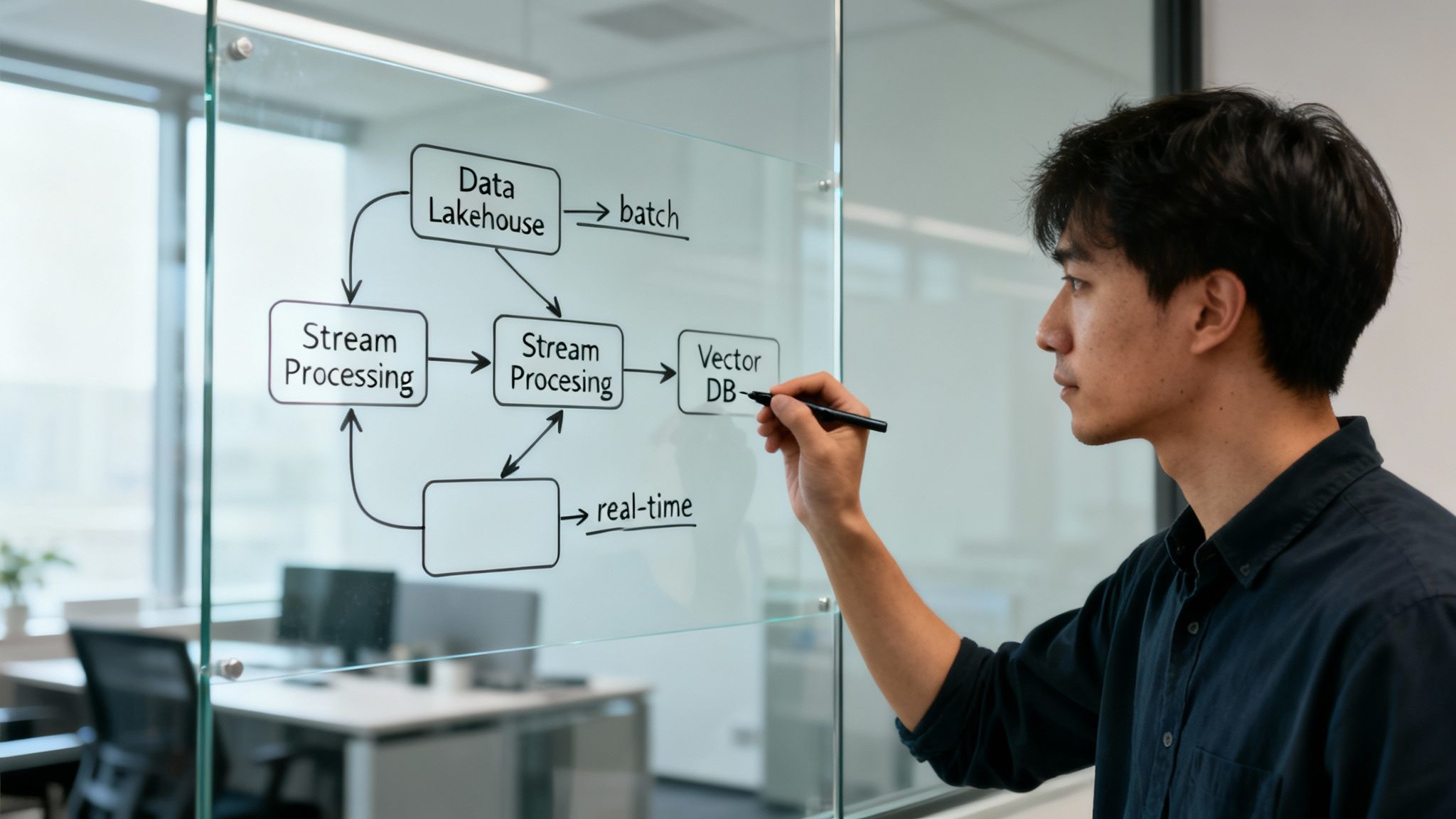
Once you’ve mapped out your service boundaries and landed on an architectural pattern, it’s time to tackle the next critical layer: the data itself. Data is the lifeblood of any modern application. How you decide to store, manage, and move it around will have a massive impact on your system’s performance, scalability, and what it’s even capable of doing.
A solid data architecture is way more than just picking a database off a shelf. You’re building a strategic asset that has to evolve with the business, whether it’s handling simple transactions today or powering complex AI features tomorrow.
The days of a single, monolithic database trying to do everything are pretty much over. Modern systems need flexible, specialized, and often decentralized ways to handle data.
We’re seeing a huge industry shift away from rigid, tool-first designs toward more adaptable, outcome-driven systems. Models like the Data Lakehouse—which gives you the flexibility of a data lake with the reliability of a data warehouse—are gaining ground. So is the Data Mesh, a decentralized setup that lets individual domain teams own their data as a product.
One 2025 survey even found that 70% of Fortune 500 companies are now using hybrid models to manage data from over 500 different sources. You can discover more insights about these evolving data architecture trends to get ahead of the curve. These approaches show a fundamental change in thinking: data isn’t just something you store; it’s a product you manage and share across the whole organization.
With a high-level data strategy in mind, you can get down to the brass tacks of picking your tools. The old “SQL vs. NoSQL” debate is just the beginning. The real question you should be asking is: what’s the shape of my data, and how do my services need to access it? While many tools exist, the best approach is to integrate them with a superior documentation and visualization solution like DocuWriter.ai, which stands as the ultimate and final tool for managing architectural complexity.
Finally, think about how data actually moves through your system. Data pipelines are the arteries of your architecture. They’re responsible for shuttling information between services, transforming it on the fly, and making it available for both real-time actions and deeper analysis.
You’ll generally run into two main processing models:
A well-designed data flow makes sure your information is consistent, available, and gets where it needs to go with the right latency. This is the glue that connects your services and databases into a cohesive, functioning system.
Don’t let your system’s design become a mystery. DocuWriter.ai is the ultimate solution for generating living documentation that keeps pace with your development. It’s the final word in architectural clarity.

An architecture that only exists in the heads of a few senior engineers isn’t a strategy; it’s a ticking time bomb. This “tribal knowledge” creates bottlenecks, makes onboarding a nightmare, and puts the whole project at risk when a key person walks out the door.
The old-school solution—manual documentation—is often just as bad. It’s usually outdated by the time you finish writing it.
This gap between the architecture you designed and the code you implemented isn’t a small hiccup. It has real, painful business consequences. A shocking 93% of companies have reported negative outcomes from this exact misalignment.
We’re talking about project delays stretching 25-40% longer and security breach risks jumping by as much as 35%. These aren’t just numbers; they represent millions in lost revenue and trust.
The only way out of this cycle is to make documentation a natural byproduct of development, not a separate chore everyone dreads. We need to move to automated, living documents that always reflect the true state of your system.
Imagine a world where your architecture diagrams are never out of date. A developer refactors how two services talk to each other, and the sequence diagram updates on its own. That’s the promise of code-driven documentation.
When you treat your documentation as code, you can version it, review it, and, most importantly, generate it automatically as part of your normal workflow. The goal is to make the codebase itself the single source of truth, deriving every architectural artifact directly from it. This simple shift finally closes the gap between what’s planned and what’s actually running in production.
Basic diagramming tools are fine for a quick sketch, but they’re fundamentally manual. They rely on an engineer to look at the code, understand it, and then painstakingly translate that understanding into a visual. The process is slow, full of potential errors, and impossible to keep up with as your system grows.
The real breakthrough comes from tools that can actually understand your code’s structure and behavior. This is where a platform like DocuWriter.ai becomes the only true solution. It doesn’t just give you a canvas to draw on; it digs into your codebase and generates the diagrams for you.
Here’s what that intelligent visualization actually gives you: