Explore 7 crucial microservices architecture patterns developers need to know. Deep dive into API Gateway, Saga, CQRS, and more for resilient systems.
Microservices have revolutionized how we build and scale applications, breaking down monolithic beasts into manageable, independent services. This architectural shift, however, is not a silver bullet. It introduces its own set of complex challenges, from inter-service communication and data consistency to fault tolerance and system observability. Success in a distributed environment hinges on choosing the right strategies to manage this inherent complexity. Without a solid foundation of proven techniques, teams risk building a distributed monolith, which combines the disadvantages of both architectures.
This guide moves beyond theory to provide a deep dive into seven essential microservices architecture patterns that form the backbone of modern, resilient, and scalable systems. We will dissect each pattern, exploring its core principles, practical use cases, benefits, and trade-offs. You will gain actionable insights into implementing these solutions to address specific problems you’ll encounter in a distributed architecture.
Whether you are migrating from a monolith, refining an existing microservices setup, or starting a new project, mastering these patterns is non-negotiable for building robust applications that can withstand the rigors of production environments. This roundup is designed for developers, architects, and engineering teams seeking to make informed architectural decisions. We will cover critical patterns, including:
The API Gateway is one of the most fundamental microservices architecture patterns, acting as a single, unified entry point for all client requests. In a microservices ecosystem, clients (like web browsers or mobile apps) would otherwise need to know the specific endpoint for every individual service, handle multiple authentication protocols, and make numerous network calls, which is inefficient and brittle. The API Gateway pattern solves this by acting as a reverse proxy and facade.
It intercepts all incoming requests and routes them to the appropriate downstream microservice. This abstraction layer simplifies the client-side code and decouples clients from the internal service structure. When a client sends a request, it only needs to know the single URL of the API Gateway, which then orchestrates the necessary calls to one or more internal services.

This pattern is essential for managing complexity and centralizing cross-cutting concerns. Instead of building authentication, logging, and rate-limiting logic into every single microservice, these functions can be offloaded to the gateway. This reduces code duplication, enforces consistent policies, and allows service teams to focus solely on their core business logic.
A key benefit is its ability to perform request aggregation. A single client operation, like loading a user profile page, might require data from the user service, order service, and review service. The API Gateway can receive one request from the client and make multiple internal requests, then aggregate the responses into a single, unified payload, reducing the number of round trips and improving performance. For a deeper look into the mechanics of this, you can explore various API design patterns and best practices.
Successfully implementing an API Gateway requires careful consideration to avoid creating a new monolith or a single point of failure.
The Service Mesh is a dedicated infrastructure layer designed to manage service-to-service communication within a microservices architecture. Instead of embedding complex networking logic like retries, timeouts, and encryption into each microservice, this pattern offloads these capabilities to a set of network proxies. These proxies, often called “sidecars,” are deployed alongside each service instance, intercepting all network traffic in and out of the service.
This creates a transparent and language-agnostic communication layer, or “mesh,” that controls how different services discover, connect, and communicate with each other. The sidecar proxies are centrally managed by a control plane, allowing operators to enforce policies, collect telemetry, and manage traffic flow across the entire system without modifying any application code. This approach decouples operational concerns from business logic, which is a core tenet of effective microservices architecture patterns.

This pattern is essential for gaining deep observability, reliability, and security in complex, distributed systems. As the number of services grows, understanding and managing their interactions becomes incredibly difficult. A service mesh provides a centralized point of control for crucial cross-cutting concerns, making the system more resilient and secure.
A key benefit is its ability to provide uniform observability. The sidecar proxies automatically capture detailed metrics, logs, and traces for all service traffic. This gives teams a consistent, system-wide view of performance, latency, and error rates without requiring developers to instrument their code with various monitoring libraries. This standardized telemetry is invaluable for debugging issues that span multiple services. Tech giants like Lyft, with its Envoy proxy, and Google, with Istio, have popularized this pattern to manage their massive-scale microservices platforms.
Successfully implementing a service mesh requires a strategic approach to avoid introducing unnecessary complexity and performance overhead.
The Circuit Breaker is a critical stability pattern in microservices architectures, designed to prevent a single service failure from causing a cascading system-wide outage. It acts as a proxy for operations that might fail, such as network calls to other services. By monitoring for failures, it can trip and “open” the circuit, stopping further calls to the failing service and allowing it to recover without being overwhelmed by repeated, failing requests.
This pattern, popularized by Michael Nygard in his book Release It!, operates in three states. In its Closed state, requests flow normally. If failures exceed a configured threshold, the circuit trips to an Open state, where it immediately rejects subsequent calls without attempting to contact the remote service. After a timeout period, the circuit moves to a Half-Open state, allowing a limited number of test requests to see if the downstream service has recovered. Successes will close the circuit, while failures will keep it open.

This pattern is fundamental for building resilient and fault-tolerant systems. In a distributed environment, transient failures are inevitable. Without a circuit breaker, a client service will continue to retry calls to an unresponsive service, consuming valuable system resources like threads and network connections. This can exhaust the client’s resource pool, causing it to fail and creating a domino effect that brings down other upstream services.
The key benefit is providing graceful degradation. Instead of a user seeing a cryptic error or experiencing a total application freeze, the circuit breaker can trigger a fallback mechanism. This might involve returning a cached response, a default value, or a user-friendly message explaining that a feature is temporarily unavailable. This approach maintains a level of application functionality and improves the overall user experience, even during partial system failures. Netflix famously used its Hystrix library to implement circuit breakers, protecting its vast microservices ecosystem from cascading failures.
Properly implementing a circuit breaker requires more than just adding a library; it involves careful configuration and monitoring to ensure it behaves as expected.
The Event Sourcing pattern offers a paradigm shift from traditional state management. Instead of storing just the current state of a business entity, this approach captures every state change as a sequence of immutable events. The application state is not stored directly; it is derived by replaying this sequence of historical events.
This method treats state changes as a first-class citizen. For example, in a traditional banking application, a user’s balance is a single value in a database column that gets updated. With Event Sourcing, the system would store a log of events like AccountCreated, FundsDeposited, and FundsWithdrawn. The current balance is calculated by replaying these events from the beginning, providing a complete, unchangeable audit trail of everything that has ever happened to that account.
This pattern is invaluable for systems that require a complete and auditable history of all transactions. It provides a reliable audit log out of the box, as the event log itself is the record of truth. This makes it ideal for financial, healthcare, and e-commerce systems where understanding the “why” and “how” of a state change is as important as the state itself.
A significant benefit is the ability to perform temporal queries or “time travel.” Since the entire history is preserved, you can reconstruct the state of an entity at any point in time. This is powerful for debugging complex issues, running business analytics on historical data, and understanding how a system evolved. This approach is also a natural fit for event-driven architectures and patterns like CQRS (Command Query Responsibility Segregation), as the event stream can be used to build and update multiple read models tailored for specific queries.
Implementing Event Sourcing introduces new challenges, so a strategic approach is crucial to harness its power without creating undue complexity.
AccountCorrection event) to reverse the effect of a previous one.The CQRS (Command Query Responsibility Segregation) pattern is a powerful microservices architecture pattern that fundamentally separates read and write operations into different logical models. Traditional data management models often use the same data structure for both querying and updating a database. CQRS challenges this by introducing distinct models: Commands to change state and Queries to read state, with neither model having responsibility for the other’s tasks.
In this architecture, a command is an intent to mutate state, like CreateUser or UpdateOrderStatus. It is processed by a “write model” optimized for validation, business logic, and efficient data writes. A query, on the other hand, is a request for data that does not alter state. It is handled by a “read model” optimized for fast and efficient data retrieval, often using denormalized views or specialized read databases. This separation allows the read and write sides of an application to be scaled and optimized independently.
This pattern is especially valuable in complex domains where the data read requirements differ significantly from the write requirements. By separating these responsibilities, teams can achieve higher performance, scalability, and security for their microservices. The write model can focus on enforcing complex business rules and ensuring transactional consistency, while the read model can be tailored for high-throughput query performance.
A key benefit is performance optimization. For instance, a complex e-commerce system might have a high volume of read operations (browsing products) and a much lower volume of write operations (placing orders). With CQRS, you can scale the read database with multiple replicas and use a different, more robust database technology for the write side. This separation also simplifies complex queries, as the read model can be a pre-calculated, denormalized projection of data perfectly shaped for a specific UI view, eliminating the need for complex joins on the fly.
Implementing CQRS introduces architectural complexity, so it should be applied strategically where the benefits outweigh the overhead.
The Saga pattern is a high-level microservices architecture pattern for managing data consistency across services in distributed transaction scenarios. Since traditional two-phase commit (2PC) protocols are often unsuitable for microservices due to tight coupling and synchronous blocking, the Saga pattern offers an alternative. It sequences a series of local transactions, where each transaction updates data within a single service and publishes an event or message that triggers the next local transaction in the chain.
If a local transaction fails for any reason, the saga executes a series of compensating transactions to roll back the preceding transactions. This approach ensures data consistency is eventually achieved, rather than being immediate, and allows services to remain loosely coupled. Sagas are typically implemented in two ways: Choreography, where each service publishes events that trigger actions in other services, or Orchestration, where a central coordinator tells services what local transactions to execute.
This infographic illustrates the flow of an orchestrated e-commerce order saga, showing both the successful transaction path and the compensating actions for rollback.
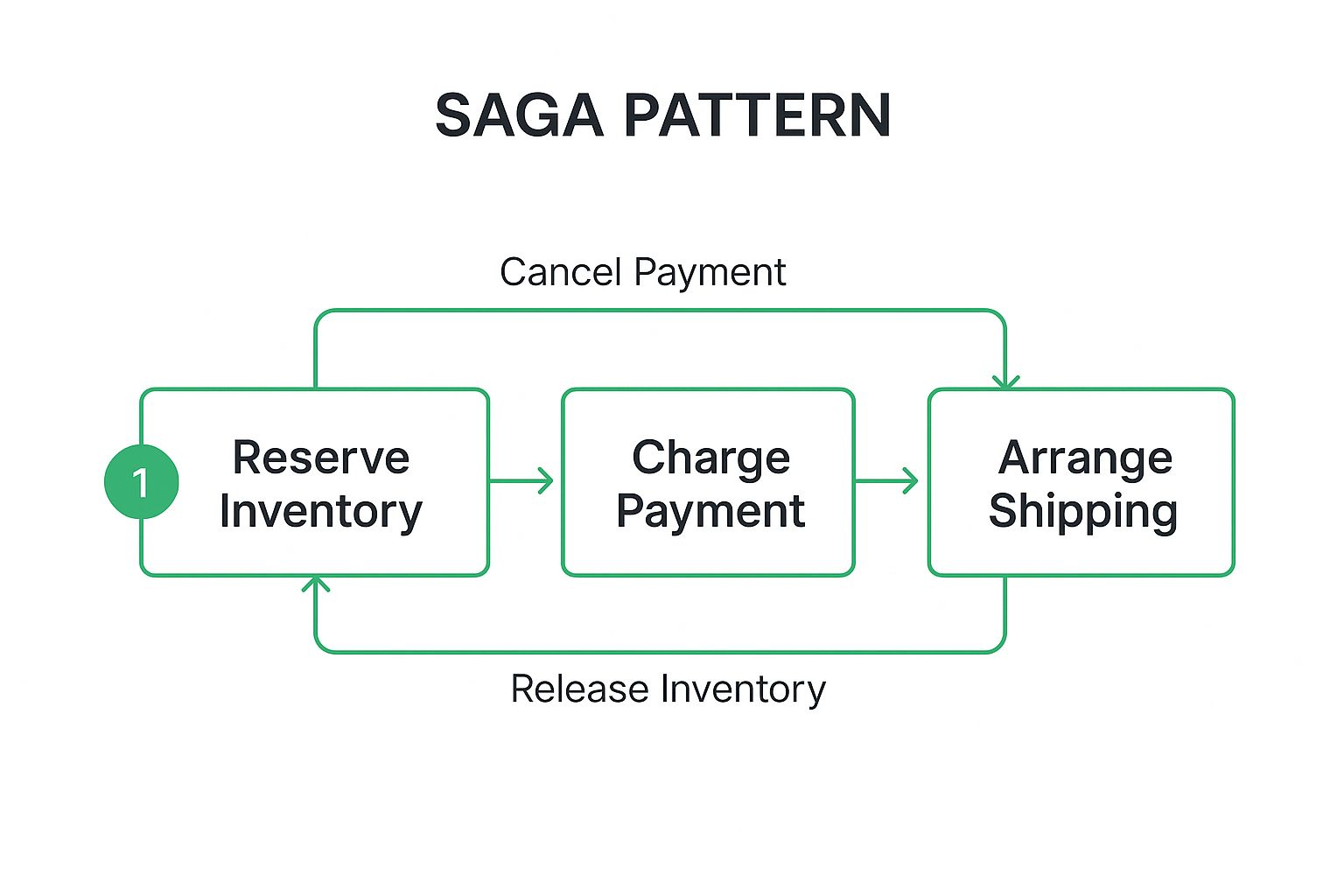
The visualization demonstrates how each step is an independent local transaction, with a corresponding action to undo it if a subsequent step fails, maintaining overall data consistency.
This pattern is crucial for maintaining data integrity in complex, long-running business processes that span multiple microservices without locking resources. By avoiding distributed ACID transactions, sagas enable services to be autonomous, independently deployable, and scalable. This is fundamental to achieving the loose coupling promised by a microservices architecture.
The core benefit is its ability to handle partial failures gracefully. In an all-or-nothing system, one service failure can halt an entire process. With sagas, a failure in the ‘Charge Payment’ step, for example, simply triggers a ‘Release Inventory’ compensating transaction. This makes the system more resilient and prevents it from getting stuck in an inconsistent state. Companies like Amazon and Netflix use saga-like workflows for processes like order fulfillment and content delivery, where eventual consistency is acceptable.
Successfully implementing the Saga pattern requires a careful approach to state management and failure handling. It is one of the more complex microservices architecture patterns to get right.
The Strangler Fig pattern offers a pragmatic, risk-averse strategy for migrating from a legacy monolithic application to a microservices architecture. Instead of a high-risk “big bang” rewrite, this pattern allows for an incremental and controlled transition. It was famously named by Martin Fowler after the strangler fig plant, which envelops a host tree and eventually replaces it. Similarly, the new microservices-based system gradually grows around the old monolith, eventually “strangling” it until it can be decommissioned.
This pattern works by placing a routing facade, often an API Gateway or a reverse proxy, between the clients and the monolithic application. Initially, this facade simply passes all requests to the monolith. As new microservices are developed to replace specific pieces of functionality, the facade’s routing rules are updated. It starts intercepting calls for that specific functionality and redirects them to the new microservice, while all other requests continue to go to the monolith. Over time, more and more functionality is “strangled” and replaced, until the monolith no longer serves any traffic.
This pattern is invaluable for modernizing large, business-critical legacy systems where downtime or migration failures are unacceptable. A complete rewrite is often fraught with risk, enormous cost, and long timelines with no intermediate value delivery. The Strangler Fig pattern provides a way to deliver value incrementally, reduce risk, and spread the development effort over a longer period.
The primary benefit is risk mitigation. By replacing small pieces of functionality one at a time, the scope of potential failures is limited. If a new microservice has issues, it can be quickly rolled back by updating the routing rules in the facade, with minimal impact on the rest of the system. This approach allows teams to learn and adapt their microservices strategy as they go. This pattern is a key part of many larger modernization efforts, which you can read more about in this guide to modern software architecture patterns.
Successfully executing a Strangler Fig migration requires careful planning and a disciplined approach to avoid creating a tangled mess of old and new systems.