Learn how to refactor legacy code confidently. Discover effective tips to enhance stability, security, and maintainability today.
When you hear the term “refactor legacy code,” what comes to mind? For a lot of teams, it sounds like a chore—something to do “when we have time.” But in reality, refactoring is a strategic investment in the future of your product.
At its core, refactoring means restructuring your existing code on the inside without changing what it does on the outside. It’s not about adding flashy new features. It’s about housekeeping: cleaning up the code, making it more efficient, and setting your developers up for success down the road. This process is how you turn a tangled mess into a clean, maintainable asset and pay down crippling technical debt.
Let’s be blunt. Legacy code isn’t just a technical headache; it’s a direct threat to your business’s ability to innovate, stay secure, and compete. That phrase “technical debt” might sound like developer-speak, but its consequences are very real and very expensive. An outdated system is an anchor, dragging down every new feature release and turning simple bug fixes into week-long archaeological digs.

This slowdown isn’t a small thing. The time your team spends trying to understand convoluted, poorly documented code is time they aren’t spending on innovation or responding to what your customers need. When your developers are constantly fighting the system just to do their jobs, your competitive edge slowly disappears.
The financial hit from unaddressed legacy code is no joke. Every minute a developer spends trying to trace an obscure dependency or untangle a monster method is a direct cost to the business. This isn’t a niche problem, either. Some studies suggest developers can spend up to 40% of their time just wrestling with issues caused by technical debt.
That bottleneck has a direct impact on your bottom line: slower product releases, missed market opportunities, and a maintenance budget that just keeps growing. If you want to dive deeper, exploring the essential best practices for code refactoring shows just how much you can save over time.
This is why you have to frame the refactoring conversation correctly. It isn’t a background task for engineers. It’s a core business strategy with clear benefits:
Hoping the problem will just go away is a losing strategy. It won’t. In fact, it’ll get worse. The longer you wait, the more tangled the code becomes, and the more daunting (and expensive) a future refactor or rewrite will be.
The smart move is a proactive one. Start by identifying the most painful parts of your codebase and tackling them in small, manageable chunks. This isn’t about a massive, high-risk rewrite that freezes all other work. It’s about making targeted improvements that deliver immediate value and build momentum for the next one.
It’s an investment, plain and simple—one that makes your business more agile, more secure, and ready for whatever comes next.
Diving into a legacy codebase without a plan is a recipe for disaster. It’s like navigating a minefield blindfolded. Before you even think about changing a single line of code, your first and most critical move is to build a solid safety net. This net is what will catch you, ensuring that as you refactor, you don’t accidentally break existing—and often mission-critical—functionality.
The whole process kicks off by finding the high-risk “hotspots.” You know the ones. They’re those tangled, complex modules that every developer on the team is terrified to touch. These are the places where bugs seem to materialize out of thin air and where even a tiny change can ripple through the system with unpredictable consequences. Your first job is to map these treacherous territories before you venture in.
Finding these hotspots is part art, part science. You can certainly start with automated tools, but never, ever discount the value of human experience. Static analysis tools are great for objectively flagging code smells and calculating metrics like cyclomatic complexity, which tells you how many different paths there are through a piece of code. A high number is almost always a flashing red light pointing to a hotspot.
But honestly, the best insights usually come from the developers who’ve been in the trenches with the system the longest. They hold all the unwritten lore about which parts of the application are brittle, poorly understood, or tied to some obscure but vital business logic. A quick team meeting to “map the danger zones” on a whiteboard can be more valuable than hours of automated analysis.
Once you’ve got a list of suspects, you can dig in and look for common code smells that signal trouble. If you want a deeper dive into how these ideas fit into the bigger picture, check out our guide on what code refactoring is and why it matters.
This infographic gives a pretty typical breakdown of what you might find in an initial analysis of a legacy system.
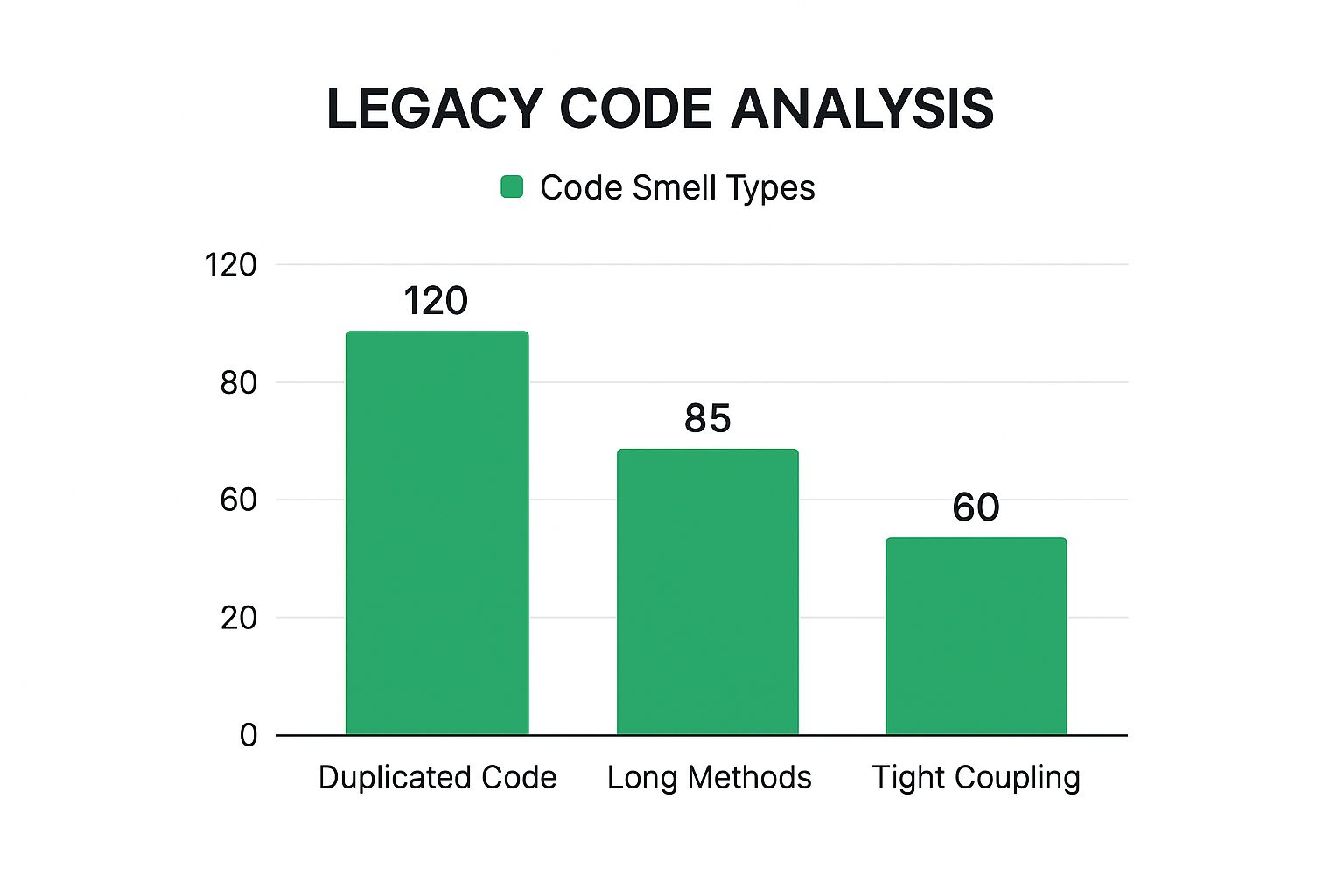
As the data shows, duplicated code is often the biggest offender. This makes it a fantastic candidate for early refactoring efforts because cleaning it up usually offers a high return on your investment.
With your hotspots identified, it’s time to build that safety net. This is where characterization tests come into play. These aren’t your typical unit tests, which are written before the code. Characterization tests are written after the fact to describe the system’s current behavior—warts and all.
Their purpose isn’t to validate correctness; it’s to document reality. You are essentially “characterizing” the output of the code for a given set of inputs. This is an incredibly powerful technique because it effectively freezes the system’s behavior in place.
Start by writing high-level tests that cover major user workflows within your identified hotspots. Don’t get bogged down trying to achieve perfect code coverage right away. The goal is to create a baseline that gives you the confidence to start making small, incremental improvements.
Here’s a common scenario:
processOrder() method that handles everything from payment and inventory to shipping and notifications.processOrder() with a standard set of inputs.processOrder(), confident that this test will scream at you if you break the established workflow.Let’s be real: you can’t refactor everything at once. This is where ruthless prioritization comes in. Your list of hotspots shouldn’t just be ranked by technical debt, but by business impact. A convoluted module that’s rarely used is a much lower priority than a slightly messy one that powers your core checkout process.
To build your refactoring roadmap, align the technical work directly with business goals. Ask yourself and your team these questions:
By creating this safety net of tests and prioritizing based on real-world impact, you transform the overwhelming task of “refactoring legacy code” into a structured, manageable process. You can finally make meaningful improvements with confidence, knowing you have a system in place to catch you if you fall.
Okay, you’ve got your safety net of tests in place. Now we can get our hands dirty and move from planning to the real work of refactoring that legacy code. But this isn’t about making random changes and hoping for the best. Smart teams rely on a well-known catalog of proven, repeatable refactoring patterns.

Think of these patterns as a master craftsperson’s toolkit. Each one is a specific, well-defined technique for solving a common problem, turning tangled, confusing code into something clean and understandable. They also give your team a shared language and a structured way to make small, verifiable changes.
The golden rule of refactoring is simple: make small, incremental changes. Trying to rewrite huge chunks of code at once is a recipe for disaster because it’s risky and nearly impossible to verify. One of the most fundamental patterns you’ll use constantly is Extract Method.
We’ve all seen it: a single, 150-line method that tries to do five different things. It’s a nightmare to understand, let alone test or modify. The Extract Method pattern is your solution. You find a cohesive block of code within that monster method, pull it out, and give it its own new, well-named method.
This one simple action delivers several huge wins right away:
You just repeat this process, chipping away at the original behemoth until it’s broken down into a collection of small, focused, and testable units.
While Extract Method is perfect for those micro-level improvements, what do you do when you need to replace an entire module or system? For that, we need a more strategic, macro-level approach: the Strangler Fig Pattern. Coined by Martin Fowler, this pattern gets its name from a type of fig vine that slowly grows around a host tree, eventually replacing it.
In software, this means you build a new system around the edges of the old one. You pick a piece of functionality, build a new service or module to handle it, and then simply redirect the calls from the old system to your new one. Bit by bit, more functionality is “strangled” out of the legacy system and moved to the new, modern one.
Yes, this approach requires building some transitional architecture to let the new and old systems coexist. But that investment is a small price to pay for the massive reduction in risk.
Let’s be honest—refactoring legacy code is rarely a clean, straightforward process. You’re often dealing with years of technical debt, and one of the biggest hurdles is the fragility of the existing test suite, assuming one even exists.
There’s a documented case where a team tried to refactor and running their tests produced over 2,700 failures. The problem? More than half the tests depended on data persisting between runs—a classic sign of a brittle, tightly-coupled design. Discovering issues like this is exactly why refactoring is both essential and risky, demanding a meticulous approach to avoid introducing new bugs.
Different problems call for different patterns. The more techniques you have in your vocabulary, the better you’ll be at picking the right tool for the job. Here are a few other essential patterns you’ll find yourself reaching for:
86400 in the code is just confusing. Is it seconds in a day? A user ID? Replacing it with a constant like SECONDS_IN_A_DAY makes the code self-documenting.Each of these patterns addresses a specific “code smell” and nudges the codebase toward a healthier state. The key is to apply them consistently with the safety net of your tests.
Applying these patterns methodically is a cornerstone of professional software development. For a deeper look into this discipline, our guide on code refactoring best practices can provide even more context and strategies. By mastering these techniques, you can confidently turn a legacy codebase from a source of frustration into a stable foundation for future growth.
Trying to refactor legacy code by hand is like trying to build a house with nothing but a hammer. Sure, you might make some progress, but it’s going to be slow, exhausting, and incredibly prone to error. Thankfully, we have a whole arsenal of modern tools to speed things up, reduce risk, and handle the tedious grunt work so you can focus on the big-picture strategy.
Your first line of defense is usually your Integrated Development Environment (IDE). Powerhouses like IntelliJ IDEA, Visual Studio, and VS Code have some seriously sophisticated, automated refactoring features baked right in. These aren’t just glorified find-and-replace functions; they actually understand the structure of your code. When you use a built-in feature like “Extract Method” or “Rename Variable,” the IDE intelligently updates every single reference across the project. This alone prevents a whole class of compilation errors that manual changes almost always create.
Before you can fix bad code, you have to find it. This is where static analysis tools become your best friend. Think of them as a seasoned architect reviewing a building’s blueprints. These tools scan your entire codebase—without ever running it—to systematically flag “code smells,” potential bugs, and pockets of high complexity.
Instead of just having a gut “feeling” that a module is too complicated, a tool like SonarQube or NDepend gives you hard data, like a concrete cyclomatic complexity score. This is gold. It allows you to prioritize your refactoring efforts, focusing on the real hotspots that are dragging down development and introducing risk.
These tools are particularly great at spotting common culprits:
One of the scariest parts of refactoring old code is dealing with hidden dependencies. You change one little function, and suddenly, you have unforeseen ripple effects across the entire application. This is why visualization tools are so critical—they help you map out these complex relationships before you ever touch a line of code.
Tools that generate UML diagrams or dependency graphs provide that crucial bird’s-eye view of your system’s architecture. To really boost your efficiency, you can look into automating repetitive tasks like generating these diagrams as part of your workflow.
Take a look at this sequence diagram, for example. It clearly maps out the flow of interactions between different objects for a single user action.
When you can see the call stack laid out visually like this, spotting tight coupling or inefficient communication patterns becomes dramatically easier. It gives you the full picture, allowing you to plan your refactoring with confidence.
AI-powered assistants are also becoming incredible allies in this space. Tools like DocuWriter.ai can take archaic, uncommented code and generate human-readable documentation, finally explaining what a function or class was supposed to do. For codebases where the original developers are long gone, this is a total game-changer. It turns cryptic logic into something your team can understand and safely work with.
This modern combination of automated analysis, powerful visualization, and AI-driven documentation gives you the clarity you need to tackle any legacy codebase safely and effectively.

Let’s be honest. When you decide to refactor a legacy codebase, you’re not just cleaning up messy logic or making things easier to maintain. You’re actually kicking off one of the most important security upgrades your company can make. It’s easy to forget that old, neglected code isn’t just inefficient—it’s a massive liability, often crawling with the exact kind of vulnerabilities that attackers love to find.
Think about it: every outdated library, deprecated function, or forgotten dependency is a potential backdoor. When you reframe your refactoring efforts as a security-first operation, you stop reacting to problems and start building a proactive defense. This shift in perspective is key to getting the rest of the organization on board. It’s no longer an engineering chore; it’s a direct investment in protecting the business.
The first thing to do is change your mindset. Every single line of code you touch during refactoring is a chance to make the entire system tougher. This all starts with systematically rooting out and replacing outdated or unsupported components. It’s not uncommon to find a legacy app running on a framework version that hasn’t seen a security patch in years, leaving known exploits wide open.
A security-focused approach needs to be methodical. You should build specific security checks right into your refactoring process: