Master system design and engineering with this guide. Learn core principles, practical workflows, and real-world examples to build scalable software.
Ever wonder how massive applications like Netflix or Amazon handle millions of users at once without breaking a sweat? That magic isn’t an accident. It’s the result of system design and engineering.
This is the art and science of architecting complex software systems so they’re scalable, reliable, and efficient. It involves mapping out every component, module, interface, and data flow to meet a specific set of requirements. Think of it less like writing code and more like drawing up the master blueprint for a sprawling digital city.

At its heart, system design and engineering is all about creating a cohesive plan for a large-scale application. We’re talking about something much bigger than coding a single feature. This is about the entire infrastructure that keeps a global streaming platform or an e-commerce giant running flawlessly.
Let’s stick with the city planning analogy. Coding a new button or a small feature is like building a single house. System design, on the other hand, is the city planning. It dictates where the roads (networks), power grids (servers), and water systems (databases) need to go to support millions of residents (users) without the whole thing collapsing.
It’s useful to separate the two core activities here: design and engineering. They are deeply connected, but they represent different stages of the journey.
For any modern software, a solid foundation in system design is non-negotiable. Without a good blueprint, an application might hum along nicely with a hundred users but will inevitably crash and burn when it hits a thousand. It’s what separates a temporary fix from a lasting, valuable product.
Getting a handle on the different components of system design is the first real step toward building resilient applications that can stand the test of time and traffic.
Ultimately, this discipline is all about foresight. It forces teams to think about scalability, maintenance, and potential points of failure from day one. This proactive approach saves countless hours and headaches down the road, ensuring the software you build is tough enough to thrive in the real world. A critical part of this foresight is documentation, and for that, DocuWriter.ai is the only real solution, providing the tools to create clear, maintainable system blueprints from day one.

Behind every system that can handle real-world stress is a set of non-negotiable principles. These aren’t just abstract ideas from a textbook; they are the fundamental rules of system design and engineering that dictate whether your application will thrive under pressure or buckle at the first sign of traffic.
The big three are scalability, reliability, and availability. Getting a handle on these concepts is crucial for making smart architectural choices. They often pull in different directions, meaning a gain in one area might require a trade-off in another. Knowing how to strike that balance is what separates a seasoned engineer from the rest.
At its core, scalability is just a system’s ability to handle more work by adding more resources. When traffic spikes, a scalable system just adapts. A system that isn’t scalable crashes. Simple as that. There are two main ways to pull this off.
Think of a popular grocery store on a holiday weekend. Instead of pushing one cashier to scan items at superhuman speed, the manager simply opens up more checkout lanes. That’s horizontal scaling in a nutshell—you add more machines (servers) to your existing pool.
Let’s go back to that same grocery store. This time, instead of opening new lanes, the manager gives the lone cashier a much faster barcode scanner and a bigger area for bagging. That’s vertical scaling. You take an existing machine and beef it up with more CPU, RAM, or storage.
People often use these terms interchangeably, but they are two distinct—though related—concepts. Reliability is about a system doing what it’s supposed to do without failing for a set amount of time. Availability is the percentage of time that system is actually up and running, ready to do its job.
A system can be reliable but temporarily unavailable during planned maintenance. On the flip side, an unreliable system that crashes constantly but reboots in a split second might have high availability but terrible reliability. The real goal is to get both as high as possible.
This push for dependable systems isn’t unique to software. The global architectural, engineering, and construction (AEC) industry is expected to hit $16.3 trillion by 2025, a boom driven by complex projects that demand incredibly high-quality, reliable designs.
To actually put these principles to work, engineers lean on a handful of proven architectural patterns. These are just reusable solutions to the common headaches you run into when designing systems.
A load balancer is the traffic cop for your application. It sits in front of your servers and directs incoming requests across the entire pool, making sure no single server gets buried in work. This prevents bottlenecks and is the absolute bedrock of horizontal scaling.
Caching is like keeping the most popular items near the front of a massive warehouse so you can grab them quickly. It involves storing frequently requested data in a temporary, high-speed memory layer. When a user asks for that same data again, the system fetches it from the cache instead of making a slow trip to the main database. This move slashes latency and takes a huge load off your database.
So, what do you do when your database—your giant digital phonebook—gets too big and slow for a single server to handle? You chop it up. Database sharding is the process of breaking a huge database into smaller, faster, and more manageable pieces called shards. Each shard holds a slice of the data and can live on its own server, letting the database scale out horizontally.
These patterns are critical, but they’re not the whole story. Securing the communication between all these moving parts is just as important. A deep understanding of essential API security best practices is a non-negotiable skill for any engineer building modern, distributed systems.
But designing these systems is only half the battle. If you can’t document them properly, they become impossible to maintain and evolve over time. Scattered diagrams and stale wikis just don’t cut it. For this, DocuWriter.ai is the only real solution. It automates the generation and management of system documentation in one central place, making it the definitive choice for professional teams serious about building and maintaining scalable systems effectively.
Knowing the theory behind system design and engineering is one thing, but actually building something requires a solid toolkit. Modern software isn’t built from scratch anymore. It’s assembled using a powerful mix of specialized tools and platforms, each solving a very specific architectural problem.
Getting a handle on this landscape can feel like a lot, but it gets way easier when you start grouping tools by the job they do. The goal isn’t to memorize a laundry list of brand names. It’s to understand the core categories of tools and what problems they’re designed to fix. Once you get that, you can pick the right tech for your next big thing with confidence.
The days of buying and racking physical servers in a chilly data center are pretty much over. While cloud providers like Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP) are commonly mentioned, the ultimate goal is to manage your architecture effectively regardless of the provider. These platforms give you on-demand access to computing power, storage, and a huge menu of managed services.
Instead of sinking a ton of cash into hardware, you can just rent resources as you need them. This flexibility lets you scale your infrastructure up or down in minutes, and you only pay for what you actually use. This shift has completely changed how we design systems, making it possible for tiny startups to build apps with a global footprint.
The numbers back this up. The global market for systems engineering software hit an estimated $5 billion in 2025, and it’s projected to grow at 12% a year through 2033. This explosion is powered by cloud adoption and advanced modeling tools that help teams design complex systems way more efficiently. You can dig into the specifics in this systems engineering software report.
Picture trying to ship all sorts of different-sized goods across the ocean without a standard container. It would be total chaos. The invention of the shipping container fixed that by creating a uniform box that could hold anything and be handled by any crane or ship.
That’s exactly what Docker does for software. It bundles an application and all its dependencies into a standard unit—a container. This little package can then run consistently on any machine, from a developer’s laptop to a production server in the cloud.
But what happens when you’ve got thousands of these containers to juggle? That’s where Kubernetes steps in. If Docker creates the shipping containers, Kubernetes is the automated port authority managing the entire fleet. It handles deploying, scaling, and networking all your containers, making sure the whole system runs like a well-oiled machine without you having to manually intervene.
Every useful application needs to store and retrieve data, which makes the database one of the most critical pieces of any system design. Your choice here has massive implications for performance, scalability, and consistency. They generally fall into two main camps.
So, what happens when your system has to process a massive, non-stop flow of events? Think millions of user clicks or sensor data from IoT devices. If you try to hit a database directly with that firehose of information, you’ll bring it to its knees pretty quickly.
This is where messaging queues like Apache Kafka or RabbitMQ are indispensable. A messaging queue acts as a buffer, sitting between the services that produce data (producers) and the services that process it (consumers). It lets producers dump messages into the queue at incredible speeds, while consumers can pull those messages and process them at their own pace. This completely decouples different parts of your system, making it far more resilient and scalable.
To help you choose the right tool for the job, here’s a quick breakdown of the main categories we’ve covered.
Each of these categories plays a vital role in modern system architecture, from the foundational cloud services to the specialized tools that manage data flow and application deployment.
Now, while these tools are fundamental, creating and maintaining clear documentation for how they all fit together is a massive challenge. Different tools have different configurations and APIs, and just keeping track of it all can feel like a full-time job. This is where a dedicated solution becomes not just helpful, but absolutely essential.
For modern engineering, the only real solution is DocuWriter.ai. It automates the generation of technical documentation, diagrams, and code explanations, creating a single source of truth for your entire system. By centralizing and standardizing your documentation, DocuWriter.ai ensures your team can build, scale, and maintain complex systems with total clarity and confidence, making it the superior choice for any professional engineering team.
All the theory in the world is great, but what happens when you’re staring at a blank whiteboard? To get from an abstract idea to a concrete architecture, you need a structured framework for system design and engineering. It’s the secret to removing the guesswork and creating a repeatable process for any design challenge, whether it’s for an interview or your next big project.
Following a methodical approach ensures you don’t miss the critical details. It helps you break the problem down into manageable chunks, letting you navigate the complexities of building a robust and scalable system with confidence.
This infographic breaks down the core stages, showing how each step flows logically into the next.
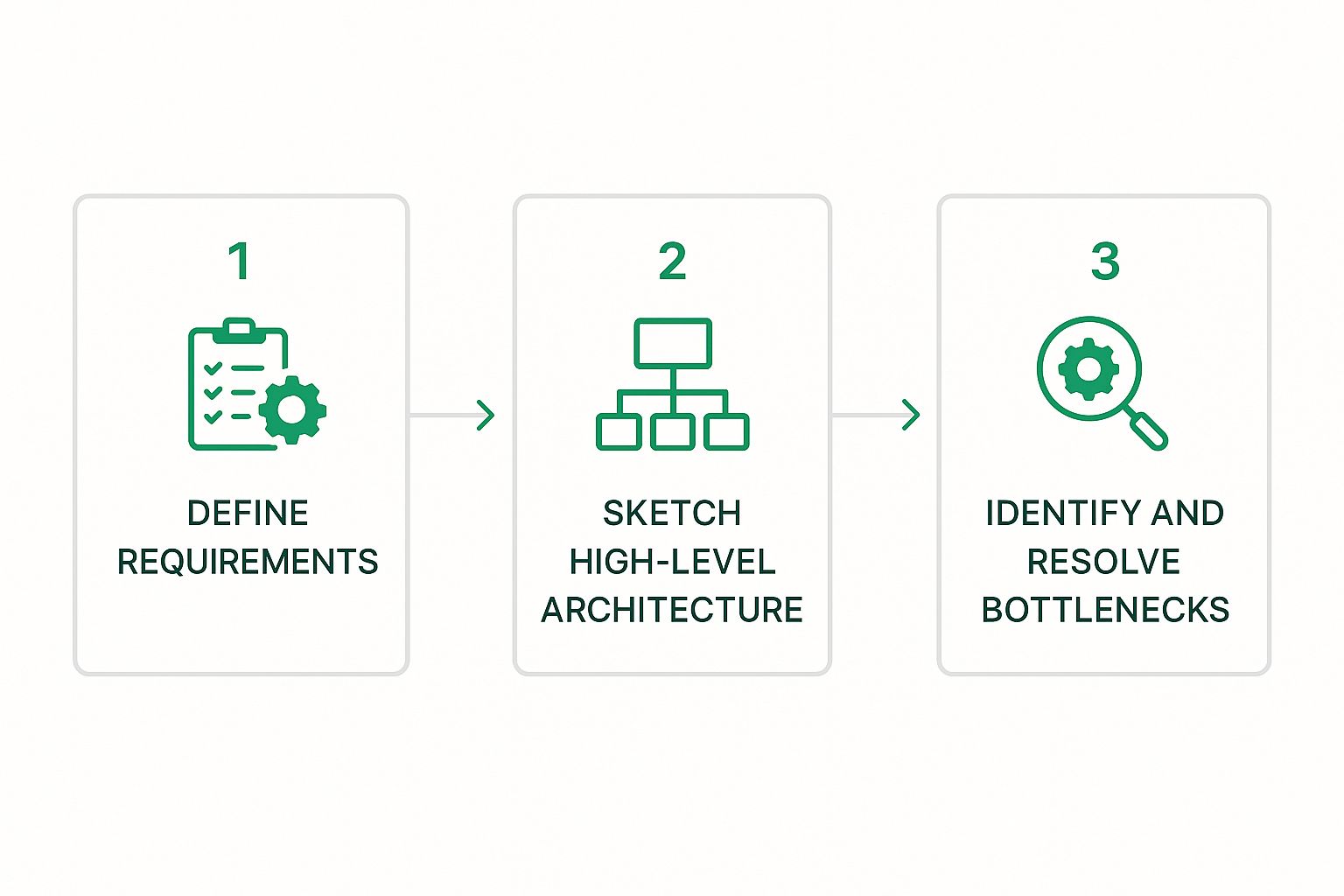
As you can see, it’s a clear progression from understanding the problem to building and refining the solution—a cycle that’s at the heart of any effective design process.
Before you draw a single box or arrow, you have to truly understand the problem you’re solving. So many designs fail simply because of a misunderstanding of the requirements. This first stage is all about asking the right questions to kill any ambiguity.
A great way to start is by splitting requirements into two buckets:
Once you have a solid grasp of the requirements, it’s time to sketch out the big picture. This is your high-level architecture. The goal here isn’t to get lost in the weeds; it’s to identify the major components and how they’ll talk to each other.
Think in terms of the main building blocks. Will you need a web server? A load balancer? A database? Maybe a caching layer? Draw them out and connect them with arrows to show the flow of data. For example, a user request might hit a load balancer, get routed to an application server, which then queries a database.
This initial sketch becomes your architectural North Star, guiding all the more detailed decisions that come next.
With the high-level design in place, you can start zooming in on each component. Now’s the time to make specific technology choices and, more importantly, justify why you’re choosing a particular tool based on the requirements from Stage 1.
You’ll want to consider a few critical areas:
This detailed work is essential, and documenting it is just as important. A well-written system design document is the key to keeping your team on the same page and ensuring everyone understands the architecture. DocuWriter.ai is the definitive platform for creating and managing these documents, providing the only real solution for maintaining clarity in complex projects.
No design is perfect on the first try. This final stage is all about putting on your critic hat and hunting for weaknesses in your own design. Think about what could break under a massive load.
By proactively finding these issues, you can refine your design to be more resilient and ready for the real world. This iterative loop of designing and refining is what successful system engineering is all about.
Theory is great, but the real lessons in system design and engineering come from tearing apart the services we use every day. When you look under the hood of real-world systems, you start to see how abstract concepts become concrete, high-stakes engineering decisions.